Designed data sync experiences that help recruiters understand, trust, and recover from automated background processes across multiple data sources.

This case study focuses on designing a trust-first data sync experience for an AI-powered recruitment platform, where data accuracy and user confidence were critical. The challenge was enabling automation across complex, multi-source data without creating uncertainty or incorrect merges.
The solution introduced manual-first profile matching, explicit confirmation before data consolidation, clear visibility into sync and enrichment states, and progressive automation with optional auto-sync. Together, these patterns made system behaviour predictable and controllable, allowing recruiters to adopt automation with confidence while maintaining data integrity.
ai.nstein is an AI-powered recruitment platform that aggregates and enriches candidate data from multiple sources to help recruiters search, evaluate, and act on talent more efficiently. As a Product Designer (UX/UI), I focused on designing the data sync experience, ensuring recruiters could clearly understand automated background processes, trust synced data, and recover confidently when issues occurred. This work aimed to reduce uncertainty around background sync operations while supporting a fast-paced, high-pressure recruitment workflow.
Recruiters rely on accurate, up-to-date data to make quick hiring decisions. In ai.nstein, candidate information was sourced from multiple systems, including internal databases, third-party integrations, and enrichment processes running in the background. Because these sync processes were largely invisible, users often struggled to understand whether data was syncing correctly, why certain information was missing or outdated, and what actions to take when errors occurred. This lack of visibility created uncertainty and reduced trust in the platform, even when the underlying systems were functioning as intended.
• Data sync processes ran in the background with limited visibility for users
• Recruiters found it difficult to understand sync status across multiple data sources
• Errors and partial sync states were not always clear or actionable
• Users were unsure whether missing data was expected, delayed, or failed
• Performance constraints required careful handling of loading, feedback, and error states
• Make background data sync processes visible and understandable
• Help recruiters trust the accuracy and freshness of synced data
• Clearly communicate sync states, progress, and issues
• Provide meaningful feedback and recovery paths when errors occurred
• Reduce confusion and support overhead related to data sync uncertainty
Product Designer (UX/UI) (Solo Designer)
Owned the end-to-end design of the data sync experience, focusing on building trust and clarity in AI-driven automation.
1 x Project Manager
1 x Business Analyst
4 x Developers
Collaborated closely with product and engineering to align UX decisions with technical constraints and data accuracy requirements.
4 months
Jira, Miro, Google Sheets, Loveable, Figma, Maze
Web platform with seamless mobile responsiveness.

Designing the data sync experience required careful trade-offs between automation, accuracy, and user trust. The following UX decisions were shaped by real client feedback and focused on reducing risk while giving recruiters confidence and control over high-impact actions.
.png)
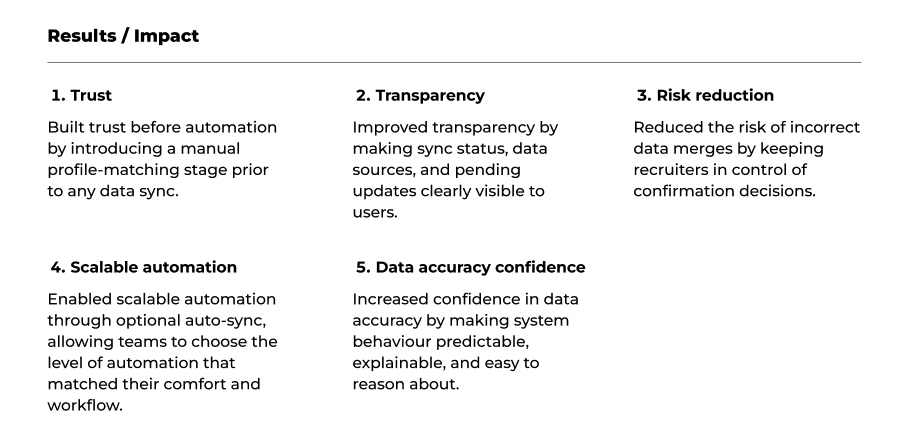
Together, these decisions prioritised trust, transparency, and user control in a high-risk data environment. By introducing automation progressively and keeping recruiters in control of critical actions, the data sync experience became more predictable, safer to use, and better aligned with the accuracy demands of recruitment workflows.
I translated the trust-first UX approach into a clear, predictable UI that reflects the source, structure, and state of multi-source candidate data. Instead of flattening everything into one profile, the interface makes sync status, match confidence, and decision points visible, so recruiters can assess data accuracy before taking action.
• High-risk actions require explicit intent (no accidental merges)
• Data state and source are visible (nothing “hidden behind” the UI)
• Automation was optional, reversible, and transparent
To evaluate whether the trust-first matching approach reduced uncertainty, I conducted moderated 1:1 sessions with five client participants, focusing on end-to-end matching and sync workflows.
Participants reported increased confidence when confirming matches, and validation remains ongoing as the product evolves.
• Users completed identity matching and sync workflows with noticeably less hesitation.
• Making data source and sync state visible enabled recruiters to validate record accuracy before merging.
• Side-by-side comparison views clarified profile differences, reducing decision friction in multi-source scenarios.
• Once data accuracy was understood, participants expressed willingness to enable automation.
• Increase clarity during identity confirmation to ensure users fully understand the implications of merging profiles.
• Simplify the unified profile layout to improve information digestibility and reduce cognitive load.
• Refine sync logic to support intentional role selection when multiple current roles are detected, ensuring accurate and aligned employment data updates.
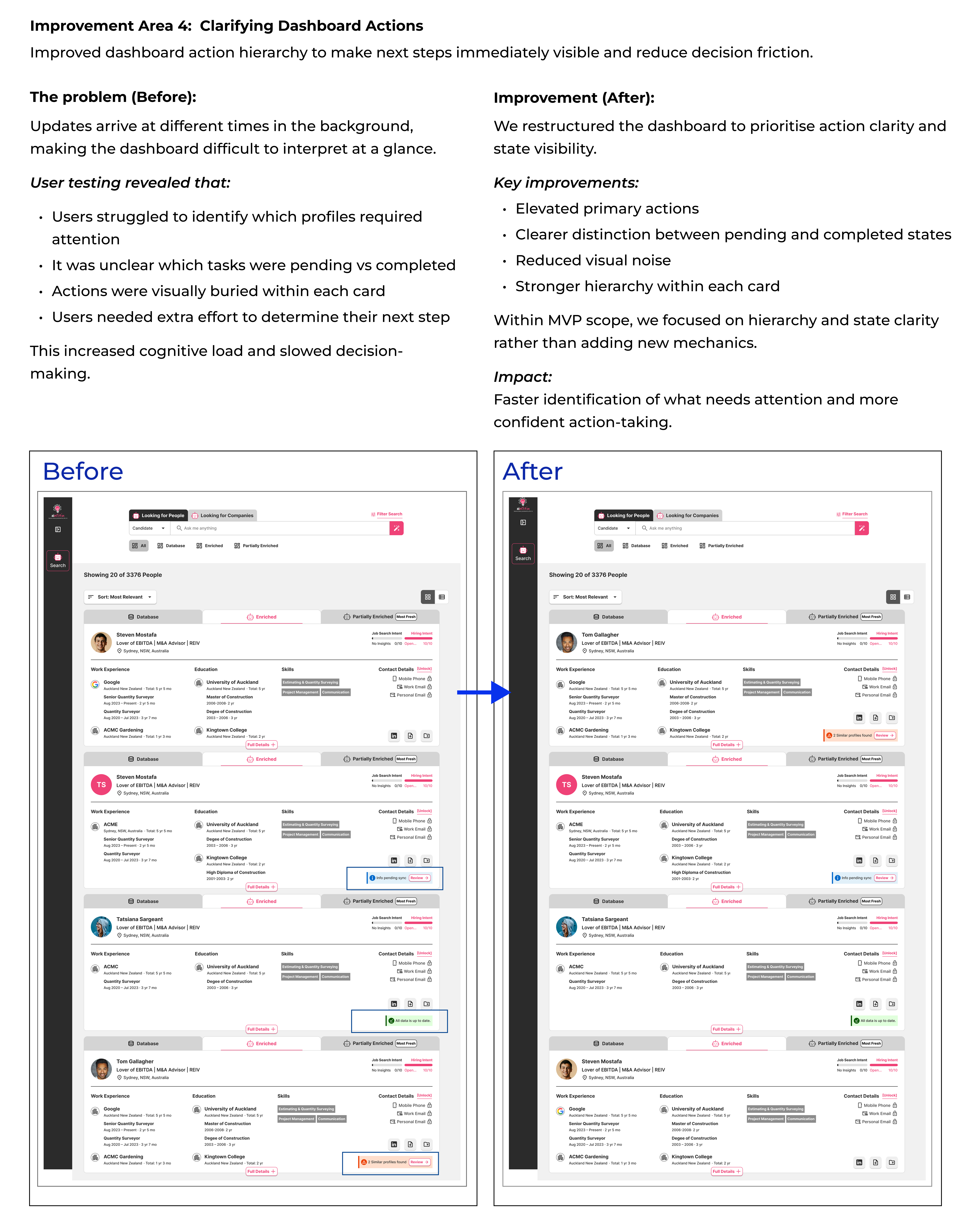
• Improve dashboard action hierarchy to make next steps clearer and reduce decision friction.
.png)
.png)
.png)
As data volume and automation adoption increase, future iterations could introduce more proactive confidence signals, such as historical sync reliability or source-level trust indicators. Additional opportunities include expanding profile-level automation controls to support teams with different risk tolerances.
As the system matures, a more unified profile view could consolidate all data sources into a single, comparable layout, making it easier for recruiters to assess differences, confidence, and accuracy at scale.
This case study demonstrates how a trust-first approach can be applied to complex, AI-driven data workflows without sacrificing scalability or efficiency. By designing the data sync experience around transparency, explicit user intent, and progressive automation, the solution transformed background system behaviour into something recruiters could clearly understand, control, and rely on.
Rather than optimising purely for speed, the design prioritised correctness and confidence at critical decision points. Manual-first matching, visible data states, and optional automation ensured recruiters remained in control of high-impact actions, while still benefiting from AI-powered enrichment as trust increased.
The outcome is a data sync experience that supports confident decision-making in high-pressure recruitment environments, balances automation with accountability, and establishes a strong foundation for future product evolution as data volume and system maturity grow.
.png)